Aug 15, 2024

Language learning has always been a challenge, and books and gamified apps can only get you so far. At some point you’re going to need to have a conversation. Speaking the language with native speakers gives one a leg up in becoming fluent, but not everyone has one of those lying around or can afford to hire one.
In this month’s OpenAI Application Explorers Meetup, Godfrey Nolan, President, RIIS LLC. demonstrated how you could utilize OpenAI’s Whisper and Gradio to build a role-playing language learning application. Short of hiring your own theater troop, it’s probably the best low stakes emulation of the real-world conversations you will need to practice to gain fluency.
You can follow along with the video or read the tutorial below, and you’ll be one step closer to your dream of language fluency.
Introducing OpenAI’s Whisper
Whisper, part of OpenAI’s suite of tools, is a powerful speech recognition engine that performs speech recognition, translation, and language identification. It can transcribe audio files and generate text in multiple languages. This technology forms the backbone of the app we’ll be building today.
Understanding Whisper’s Capabilities
Whisper offers several key functionalities:
Transcription: Whisper can convert speech to text accurately.
Translation: It can translate audio from one language to another.
Text-to-Speech: Whisper can generate spoken audio from text input.
Multiple Language Support: It supports dozens of languages, from Afrikaans to Vietnamese.
Transcription
Here’s a basic example of using Whisper for transcription:
This function takes an audio file as input and returns the transcribed text using Whisper’s transcription capabilities. It uses a file of a famous Steve Job’s speech. If you were to run it, you’d get something like this:
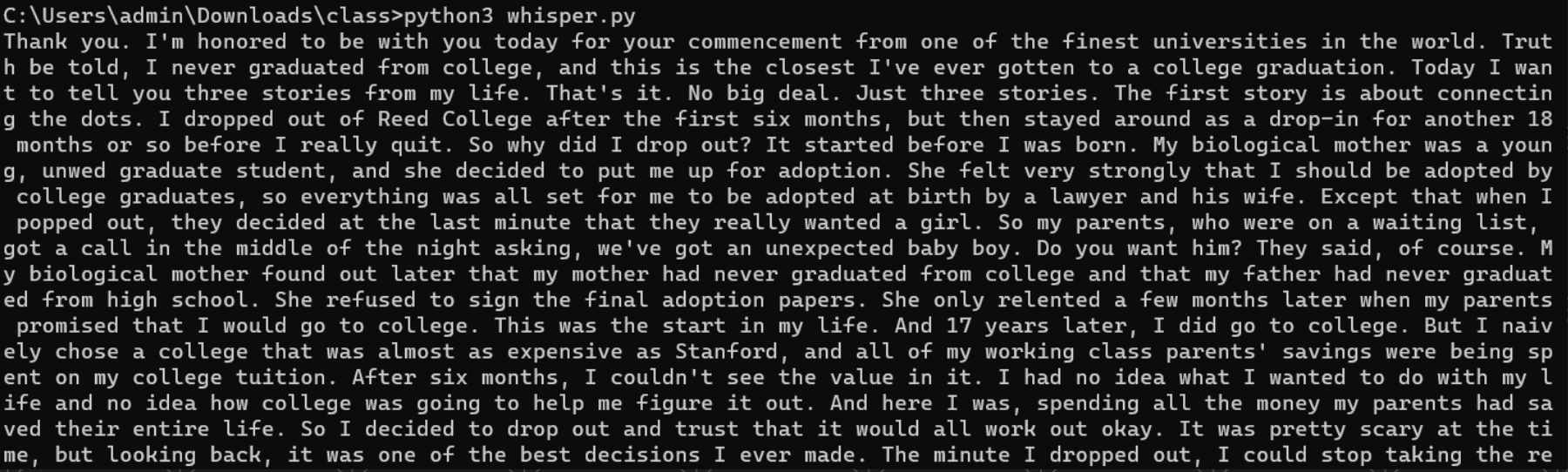
Text-to-Speech
Whisper also provides text-to-speech functionality:
This function generates an audio file of the input text being spoken.
Translation
The final key to the puzzle is Whisper’s translation functionality.
The resulting response of this should be “The quick brown fox jumped over the lazy dog.”
Building a Language Learning System
By combining ChatGPT’s conversational abilities with Whisper’s speech recognition and synthesis capabilities, we can create a powerful language learning tool. The basic flow of such a system would be:
The learner speaks a phrase in their target language.
Whisper transcribes and translates this input to English.
ChatGPT generates an appropriate response based on the context.
The response is translated back to the target language.
Whisper converts this text response to speech, which is played back to the learner.
Implementing the System
To implement this system, we’ll use Gradio, a Python library for creating simple web interfaces for machine learning models. As you can see here, the interface is quite svelte for such an easy-to-implement framework.
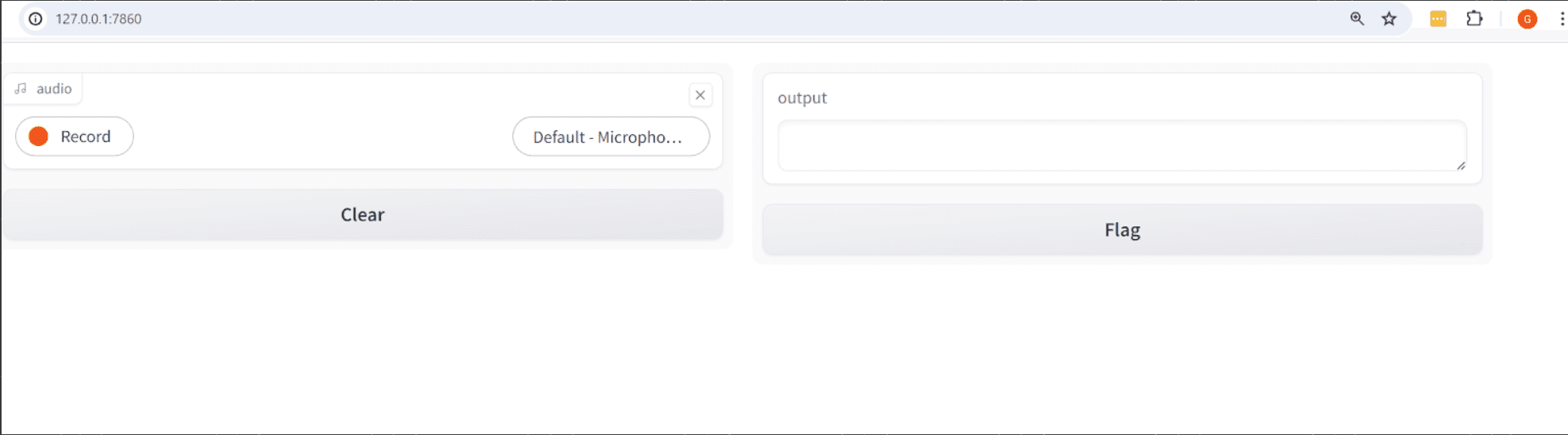
If you haven’t already use a pip command to install Gradio.
Also, let’s intall PyAudio, which if you can’t already tell by the name will be pretty helpful.
Create a file and name it app.py. Then import the following at the top:
The next thing we are going to do is create a msgs list variable. We are going to pre-load it with our first item, the system directive. This puts up some guard rails for how the OpenAI can interpret and respond to our user prompt which will be coming later.
You’ll notice our role for this is set to system. Our next role and content pair will be the ‘user’, and the prompt.
Now let’s go step-by-step using the Whisper features we learned earlier to implement our role-playing language coach.
In this code, the transcribe function is taking us on a world tour of using OpenAI's speech and translation APIs to process an audio file. First, it opened up the audio file and used the Whisper model to transcribe French audio into English text. If the text was longer than 10 characters, it added this text to a global list called msgs and printed it out for us. Then, it generated a response with the GPT-3.5-turbo model, added that to msgs, and printed it.
We’ve got two more steps to go but we need to take a bit of a pause because Step 4 is the one of the more complicated steps.
This is where it translates the English response into French and turns that French text into audio using the tts-1 text-to-speech model, streaming the audio output. Our PyAudio library comes in handy here. You’ll notice in the code we had to set up some parameters to make this happen. Step 5 is rather easy. We just update our text on screen with the response.
Now to take advantage of that Gradio install earlier we are going to create a simple interface for this system:
Alright, let's dive into what this snippet is doing! Here, we're using Gradio to create an interface for our transcribe function. The gr.Interface is set up to call the transcribe function whenever it receives input. We've got it configured to take audio input directly from a microphone, with the audio being streamed as a file path. The output is then displayed as text. By setting live=True, we're making sure that the interface processes the audio input in real-time. Finally, the .launch() method kicks everything off, opening up the interface so users can start interacting with it.
Basically, this creates a web interface where users can speak into their microphone and receive text responses in real-time. Gradio is super powerful and this is only one of the things it does, so check it out when you have time.
Conclusion
Throughout this guide, you learned how to create an interactive language learning tool using OpenAI's Whisper and ChatGPT models, combined with Gradio for a user-friendly interface. You explored how to transcribe and translate spoken language, generate responses, and convert text back into speech, all while understanding the integration of these technologies. By implementing these steps, you gained practical experience in building a real-time application that allows users to practice language skills by speaking into a microphone and receiving text responses. On top of all that, you now can build upon these principles to create a fully customizable language coach!
