Oct 14, 2024

Everyone who uses LLMs regularly has had to confront the problem of hallucinations, but not everyone has heard about Retrieval-Augmented Generation and its ability to improve your LLMs responses by providing source material for context.
In a recent OpenAI Application Explorers Meetup, Godfrey Nolan, President, RIIS LLC., created both a RAG application that could query a set of source documents and a secondary app that could create multiple choice questions from the sources too. It’s essentially like building your own tutor who you can train on any subject matter.
This article will explore the fundamentals of RAG, its implementation using LangChain, and how it can be integrated with OpenAI’s models to create more intelligent and context-aware AI systems. As per usual, you can follow along with the video version or the written one below.
Understanding RAG: Retrieval-Augmented Generation
Retrieval-Augmented Generation, or RAG, is a method that combines the power of large language models with information retrieval systems. The concept might sound complex, but its core idea is simple, enhance the output of AI models by providing them with relevant, up-to-date information from external sources. As you can see in the example below, this mirrors traditional data retrieval methods, with the main exception being that the data is in unstructured text.
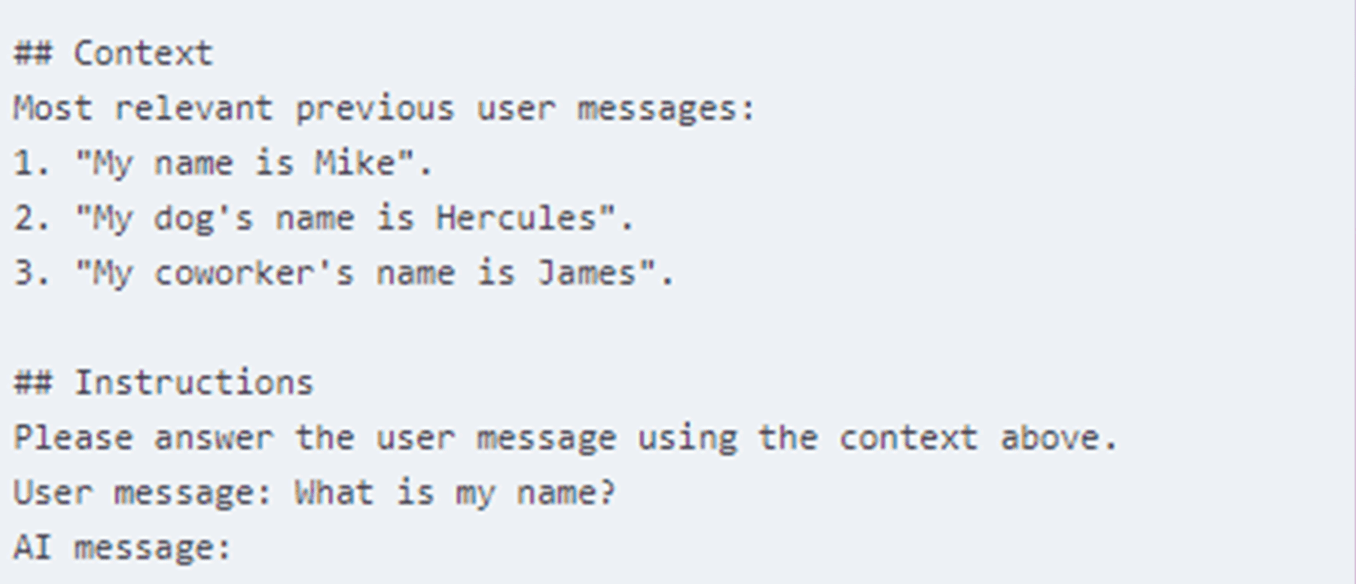
RAG addresses one of the key limitations of traditional language models: their reliance on pre-trained knowledge that can become outdated. This process allows the AI to provide more accurate, up-to-date, and contextually relevant responses.
How RAG Works
Here’s a more detailed breakdown of how RAG works:
Document Ingestion: The system takes in various documents, such as PDFs, web pages, or databases.
Chunking: These documents are broken down into smaller, manageable pieces of text.
Embedding Creation: Each chunk is converted into a vector representation (embedding) that captures its semantic meaning.
Storage: These embeddings are stored in a vector database for quick retrieval.
Query Processing: When a user asks a question, the system finds the most relevant chunks from the database.
Context Augmentation: The retrieved chunks are used to augment the context given to the language model.
Response Generation: The model generates a response based on the augmented context and the original query.
The Power of Embeddings
At the heart of RAG lies the concept of embeddings. Embeddings are dense vector representations of words, sentences, or even entire documents. Essentially, they break words down into numbers. They capture the semantic meaning of text in a way that computers can understand and process more efficiently. Embeddings allow us to find similar pieces of text by comparing their vector representations, a process that’s much faster and more effective than traditional keyword matching, but comes with its own pitfalls (hallucinations).
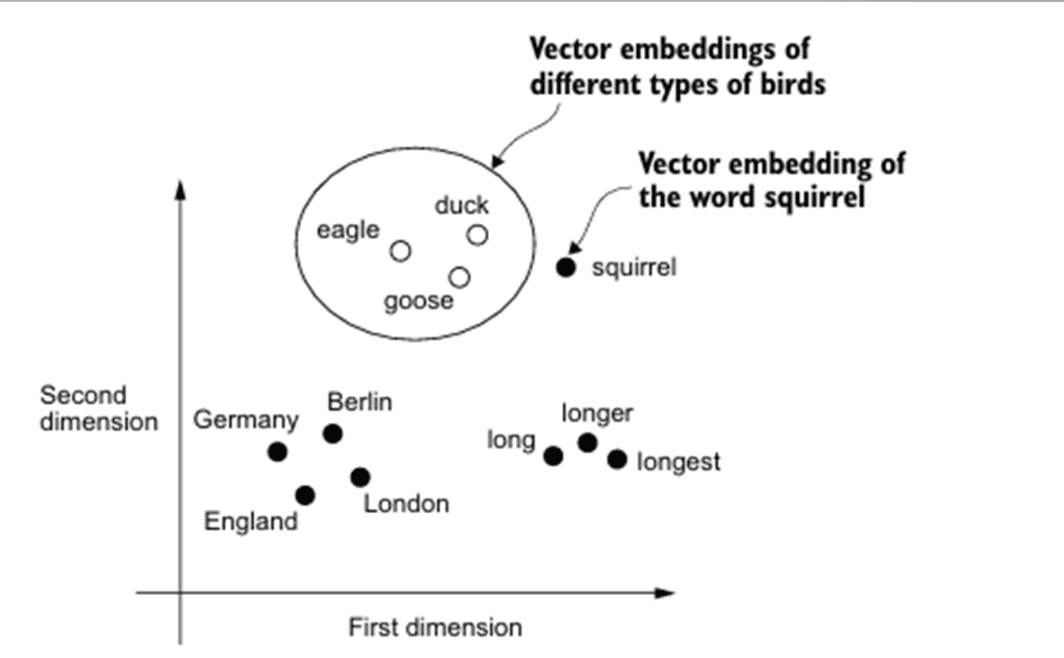
For example, when using OpenAI’s embedding model, we might generate an embedding for a movie title like this:
When we need to find information related to this movie, we can quickly compare its embedding to the embeddings of other text chunks in our database.
And just for curiosity's sake, here’s what an embedding looks like:
Introducing LangChain
While RAG is powerful on its own, implementing it from scratch can be challenging. This is where LangChain comes into play. LangChain is a framework designed to simplify the process of building applications with large language models.
LangChain provides a suite of tools and abstractions that make it easier to work with language models, handle document loading, manage vector stores, and create complex chains of operations. It acts as a high-level interface to various AI models and utilities, allowing developers to focus on building applications rather than wrestling with low-level details.
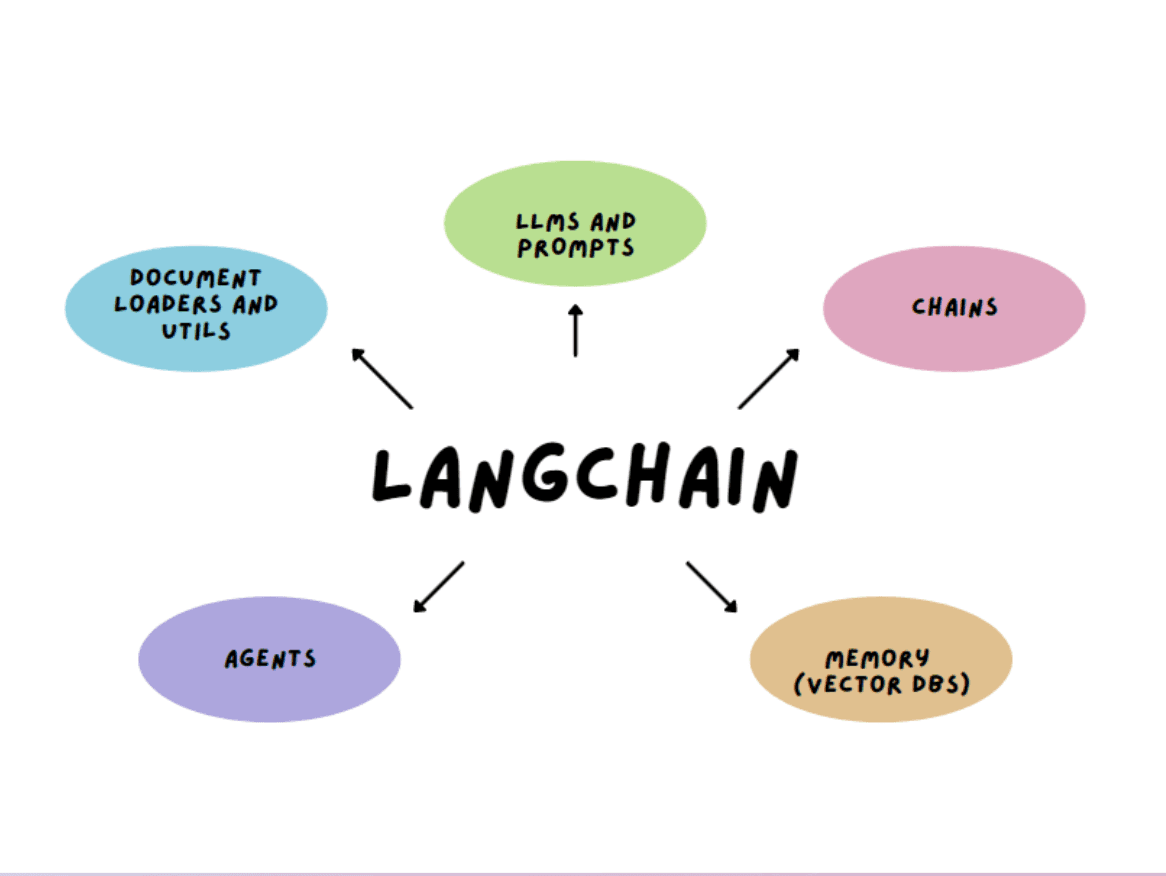
One of the best features of the LangChain is you get context memory for free with no extra coding. We’ve all been in situations where an LLM doesn’t utilize an important piece of data that was previously stated in the conversation.
To get started with LangChain open your terminal and use pip install langchain langchain_openai. If there are other LLMs you want to use, look up the name of the corresponding library to install.
Here’s a simple example of how you might set up a basic LangChain application:
This snippet demonstrates how LangChain simplifies interactions with OpenAI’s chat models, handling the API calls and message formatting behind the scenes.
Here’s an expected response, terrible joke included:
And a cheesy emoji too!
Building a RAG System with LangChain
Now that we understand the basics of RAG and LangChain, let’s explore how we can combine them to create a powerful question-answering system. We’ll build a system that can ingest PDF documents, store their contents efficiently, and answer questions based on the information within those documents.
First, let’s look at how we might set up our document loading and vector store creation:
This code sets up a class that can load PDF documents from a specified directory. The load_documents method iterates through PDF files in the given directory and loads their contents.
This method checks if a vector store already exists. If it does, it loads the existing store. If not, it creates a new one by splitting the documents into chunks, creating embeddings, and storing them in a FAISS vector store. We did something similar on the text-splitting front without the vector store in a previous tutorial, so check that out too for another use case.
You may ask, “What’s a FAISS vector store?” A FAISS stands for Facebook AI Similarity Search and is a vector store, a specialized database designed to efficiently store and search high-dimensional vectors, enabling rapid similarity searches on large datasets for applications developed by Meta.
Next, we’ll set up the question-answering chain:
This part of the code sets up a question-answering chain using LangChain’s RetrievalQA class. It uses the vector store we created earlier to retrieve relevant context, which is then fed into the language model along with the user’s question.
With this foundation, we’ve created a basic RAG system that can ingest PDF documents and answer questions based on their contents.
Testing the system
Okay, so we have a way to upload the files and retrieve them for the relevant answer. We also set up a chain to pull in the appropriate information from those documents for ‘context’ in our prompt. Now, we need to create the main() to test if it is functioning as intended.
The above code starts by creating our PDFRAG object, then, it kicks off a simple chat-like interface where you can type in questions about your PDFs. We are asking it to display the relevant docs, so we can test if it is able to parse our documentation correctly. If the answers are truly off-base, try adjusting the chunk_size or chunk_overlap variables. Let’s ask it a simple question and check what it comes up with:
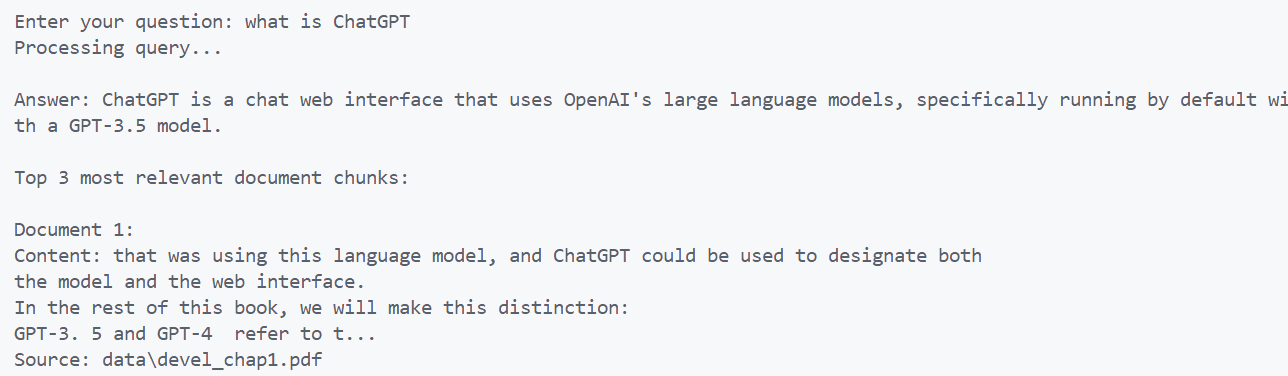
Nice! We can tell it’s pulling from the uploaded docs!!!
Enhancing the RAG System
Now that we have established our basic RAG system, let’s explore some ways to improve and extend its functionality. We’ll focus on generating multiple-choice questions, saving the vector store for efficiency, and updating the system with new information.
Generating Multiple-Choice Questions
One powerful application of our RAG system is to generate multiple-choice questions based on the ingested documents. This can be particularly useful for creating study materials or practice tests. Let’s modify our code to accomplish this:
This code sets up a new class PDFMultipleChoiceGenerator that uses the vector store to retrieve relevant context and then generates multiple-choice questions based on that context. The setup_chain method creates a prompt template that instructs the language model to create questions solely based on the provided context, ensuring that the questions are relevant to the ingested documents.
Updating the Vector Store
As new documents become available or existing documents are updated, we need a way to update our vector store without recreating it entirely. Here’s a method to accomplish this:
This method loads new documents, splits them into texts, and adds them to the existing vector store. It then saves the updated store for future use.
Putting It All Together
Let’s update our main function and change it so that it ties all these components together:
And what does that yield?

Conclusion
By leveraging the power of LangChain and OpenAI’s language models, we’ve created a robust system that can ingest PDF documents, understand their content, and generate relevant questions based on that content. This system has numerous potential applications, from creating study materials for students to assisting teachers in exam preparation.
